Web scraping, programmatically going over a collection of web pages and extracting data (Datacamp) is a useful tool for anybody working with data. It provides you so much more opportunities in the analysis! For example you need more data or you have found that some extra data about weather will be so much helpful. You can analyze data that you really want (vegan recipes, Sephora products, instagram posts, pictures of 🦒) or these. And just being familiar with the ways you can extract the data will help a lot in future.
I haven’t dived deep in that topic but just having sense of how powerful it is and what can I do with just basics is helpful and inspires for so many more projects!
So here is super basic project of scraping Amazon page.
One more thing, you can actually use some ready made API (it is when you can access some data storage and get data from there) or web crawlers specific for you need. Don’t know how much they cost, they can be free for some limited amount of pages or time so better do web scarping yourself (but if you have money and no time then ready made solutions are easier ).

And another small thing. Sometimes it is not legal to scrape the webpage. Check it by appending “/robots.txt” to the URL. For example: https://www.amazon.com/robots.txt. Then you can see the Disallow command which tells you (user-agent) not to access the webpage(s).

Let’s start the project
1. Choose a web page (url).
I chose Amazon
For one company, I was doing a project where I had to look for automatic pet feeders. Something like these:
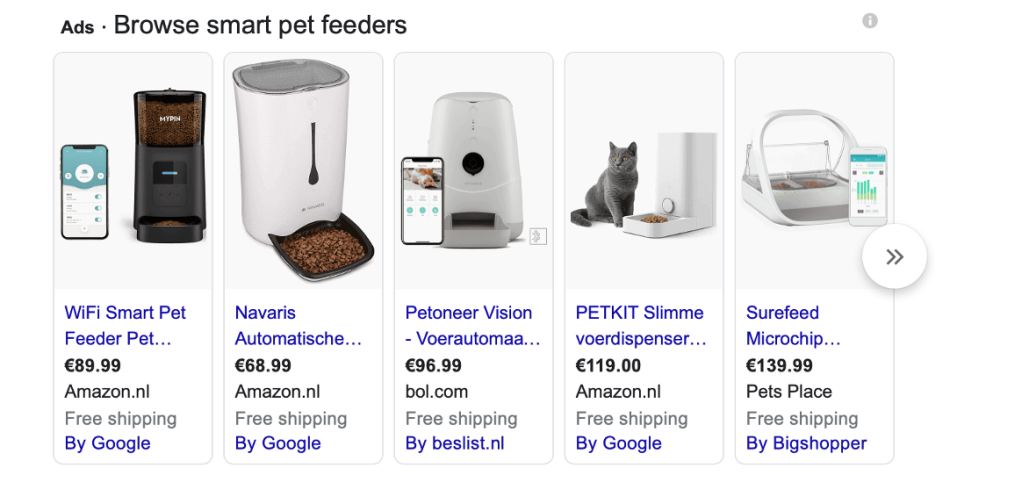
So I decided to extract products from Amazon as it is the most familiar and favourite e-commerce platform for me. Anyway I think it is popular in any country, which means more data, more reviews, more products! And we are hungry for data.
Choosing library: Beautiful Soup
You can read more here, but in general Scrapy is powerful, uses some non-blocking mechanisms, faster, robust, can be migrated (good for large, complex projects with pipelines, proxies) uses XPath and CSS expressions (I don’t know all the benefits but it seems as it is the most efficient of all python web scraping libraries). Can also use proxies and VPNs and send multiple requests from the multiple proxy addresses.
Selenium is used to automate test for Web Application and also to develop web spiders. For Core Javascript websites.
The easiest and most beautiful is BeautifulSoup (nice name 🙂 ). However it is dependant on some other libraries (not good for complex projects) like to make request to a server and a parser. But it is easier to use! (which is beautiful!)
(Also you can be blocked if you scrape more than some limited amount)
I chose BeautifulSoup as it is easier for beginners (me).
Anaconda: conda install -c anaconda beautifulsoup4
3 Coding
python <-this url I scrape
Starting with imports. By the way I just tried to find some similar notebooks about web scarping Amazon and combine several, and adapt it to my goal.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import re
import time
from datetime import datetime
import matplotlib.dates as mdates
import matplotlib.ticker as ticker
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
import nltk
nltk.download('punkt')
from nltk.corpus import stopwords
import stringBasically all the useful info I took from here Datacamp. Check it.
If we go step by step in this code. Num of pages. We can go through several pages if they have similar address and only one variable (page number). For example:
https://www.amazon.nl/-/en/s?k=automatic+feeder&s=review-rank&page='+str(pageNo)+'&language=en&crid=3C66TWN033GOV&qid=1615298484&sprefix=automatic+feeder%2Caps%2C148&ref=sr_pg_'+str(pageNo)
we can insert in the url of the address the variable pageNo. However I noticed pages are changing their address depending how you accessed it. It is actually really hard to scrape Amazon. So it is ok to start with one page. Which I do.

Next we see the headers. They specify your browser, your ID in order to pass along the get method. From Datacamp : help to bypassing the detection as a scraper. I think it is useful 🙂
Next specify the url (see above about pageNo) and requests help you to get information. The content is extracted from that page. Then we need to create a Soup variable soup = BeautifulSoup(content). Then we can go through soup.
But first a little of html. This scary picture below. To get such, right click anywhere on your page and press Inspect Element.
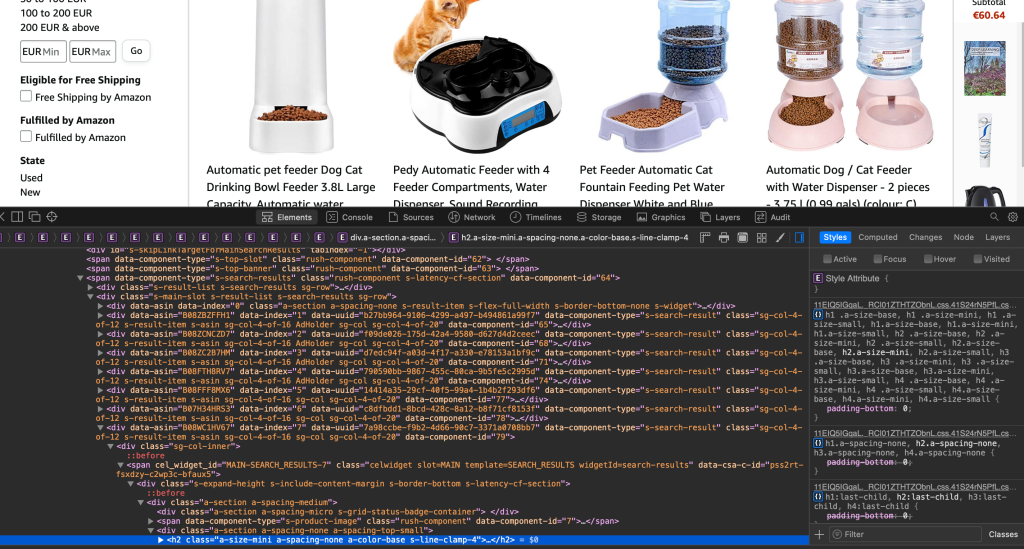
All you see is a code for each little element on the web page. It is good to know the basics of html and javascript. But it can be seen as some tree. Each branch is like so big element. For example all the products are part of some branch which has tag div. And then every item has it’s own branch and it contains picture, description, price, review, etc. When you navigate through page you can see where in the code it is highlighted. It means there is a code that generated that item with all those descriptions, cute picture.
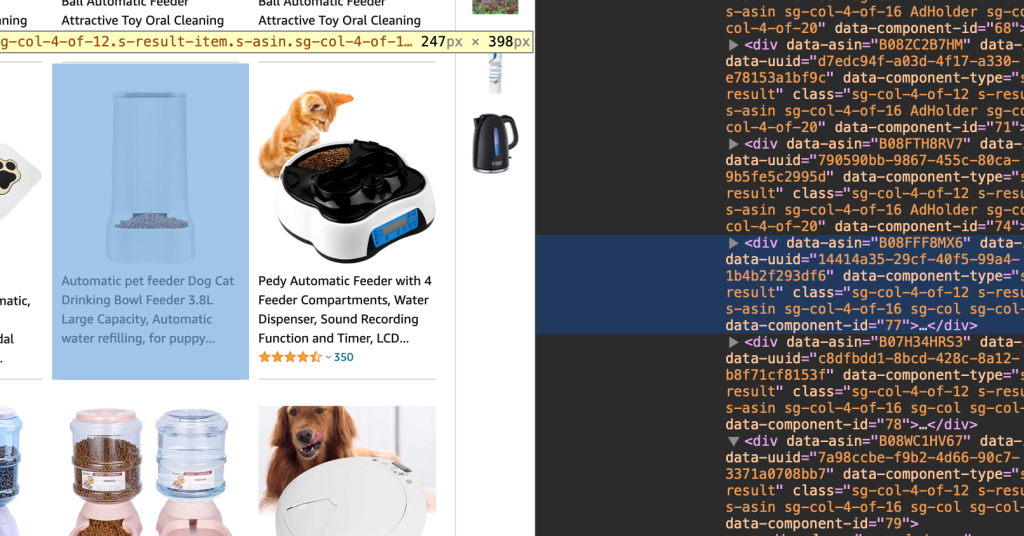
We you soup.findAll and we try to find elements of the page using its HTML tag (like div, or span, etc.) and/or attributes: name, id, class, etc (Datacamp).
I chose div ‘a-section a-spacing-medium‘ as the tree to extract info about products. I loop inside it to find relevant tags.
for d in soup.findAll('div', attrs={'class':'a-section a-spacing-medium'}):
print(d)
What we get if we print d, look carefully and can see for example description underlined with red.
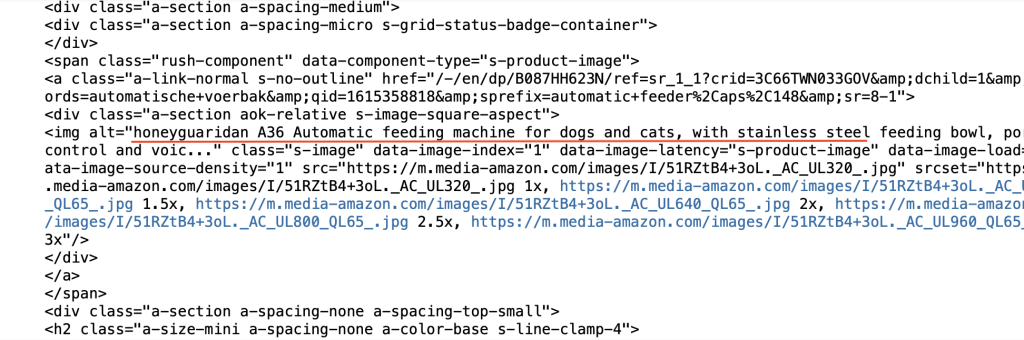
Some examples to find tags for name and review
Name tag (all those we find by inspecting or using extra resources (see References to find proper tags. Manual job)
name = d.find('span', attrs={'a-size-base-plus a-color-base a-text-normal'})

Review tag
rating = d.find('span', attrs={'class':'a-icon-alt'})

no_pages = 7
def get_data(pageNo):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept-Encoding":"gzip, deflate", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "DNT":"1","Connection":"close", "Upgrade-Insecure-Requests":"1"}
r = requests.get('https://www.amazon.nl/-/en/s?k=automatic+feeder&s=review-rank&page='+str(pageNo)+'&language=en&crid=3C66TWN033GOV&qid=1615298484&sprefix=automatic+feeder%2Caps%2C148&ref=sr_pg_'+str(pageNo), headers=headers)#, proxies=proxies)
content = r.content
soup = BeautifulSoup(content)
alls = []
for d in soup.findAll('div', attrs={'class':'a-section a-spacing-medium'}):
print(d)
name = d.find('span', attrs={'a-size-base-plus a-color-base a-text-normal'})
#n = name.text
#print(n[0]['alt'])
rating = d.find('span', attrs={'class':'a-icon-alt'})
users_rated = d.find('span', attrs={'class':'a-size-base'})
#d.find('a', attrs={'class':'a-size-base'})
price = d.find('span', attrs={'class':'a-price-whole'})
all3 = []
if name is not None:
#print(n[0]['alt'])
all3.append(name.text)
else:
all3.append("unknown-product")
if rating is not None:
#print(rating.text)
all3.append(rating.text)
else:
all3.append('-1')
if users_rated is not None:
#print(price.text)
all3.append(users_rated.text)
else:
all3.append('0')
if price is not None:
#print(price.text)
all3.append(price.text)
else:
all3.append('0')
alls.append(all3)
return(alls)Then you just append all the findings into some variables.
results = []
for i in range(1, no_pages+1):
results.append(get_data(i))
Saving everything in a data frame and csv for later usage.
I so so love when I have my data saved as data frame and I can do now everything with it. Honestly, the steps above were not familiar to me, I have never done web scraping before and never used those libraries. So I could make mistakes but the fact that I got everything in my familiar format makes me feel happy 🙂
flatten = lambda l: [item for sublist in l for item in sublist]
df = pd.DataFrame(flatten(results),columns=['Name','Rating','No_Users_Rated', 'Price'])
#df.to_csv('amazon_products.csv', index=False, encoding='utf-8')Got thiss 🤖

Sort, group, combine and do whatever you want!
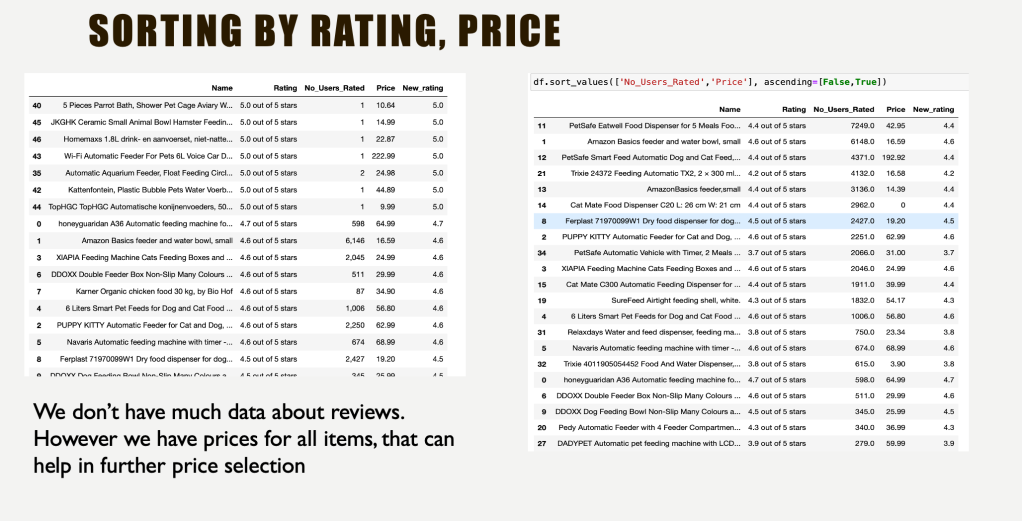
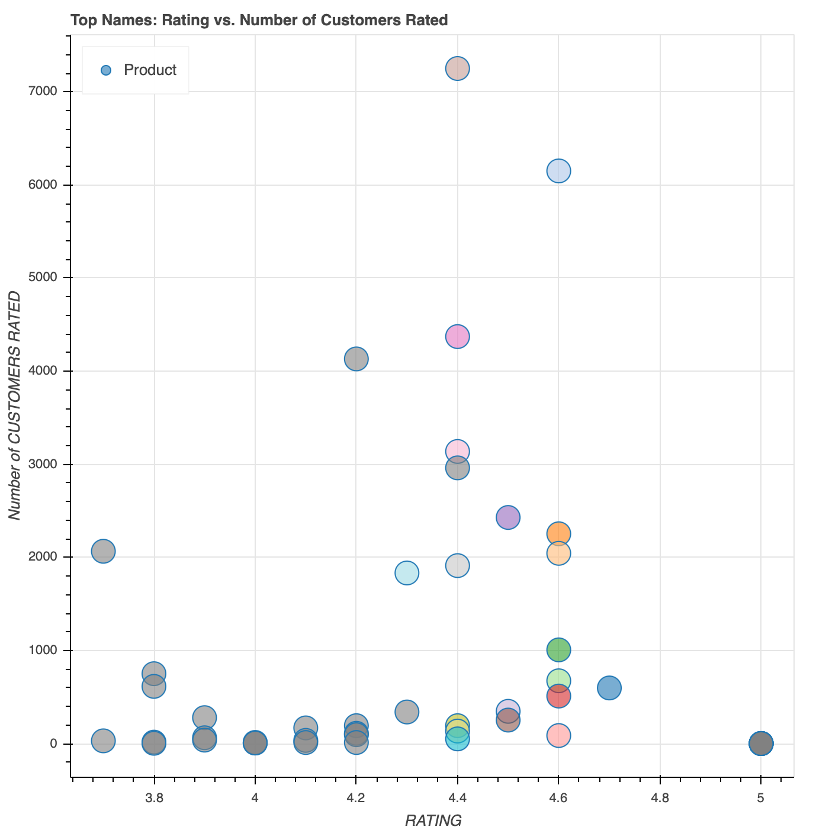
Of course visualise 🤩
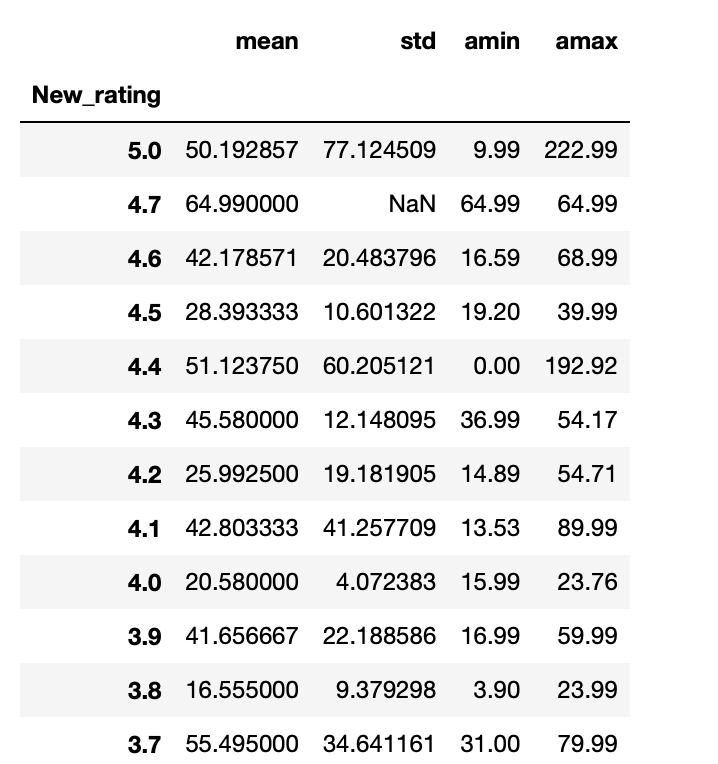
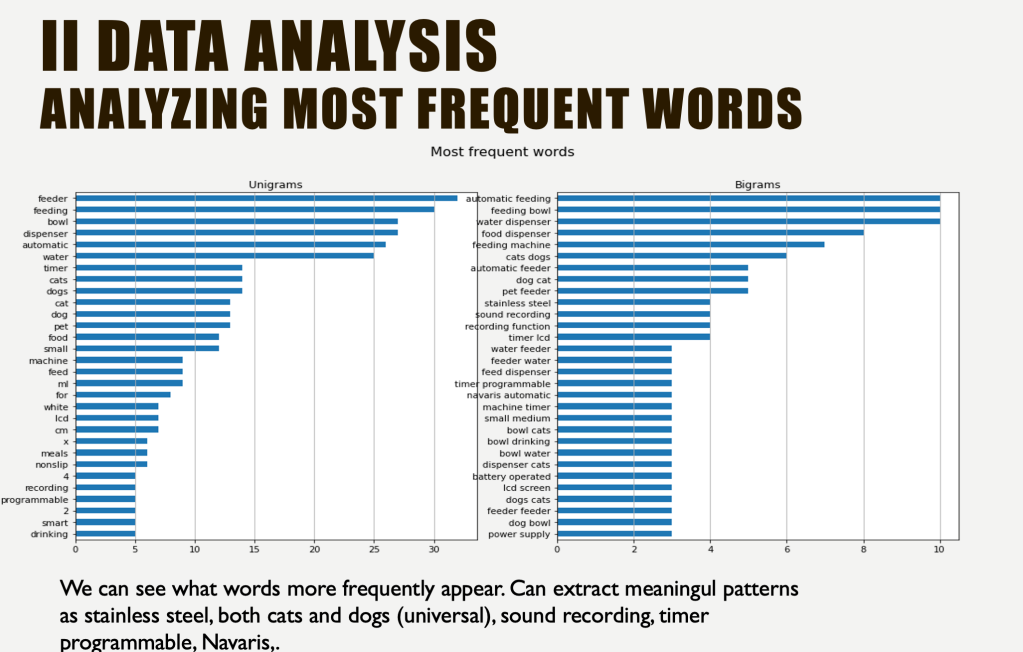
Also I had search for reviews, do sentiment analysis to find out whether you should buy it for your pet.
for d in soup.findAll('div', attrs={'id':'cm-cr-global-review-list'}):
print(d)
name = d.find('div', attrs={'class':'a-section review aok-relative cr-desktop-review-page-0'})
#rating = d.find('span', attrs={'class':'a-icon-alt'})
print(name)
Available on my GitHub.
References:
https://www.edureka.co/blog/web-scraping-with-python/
https://www.datacamp.com/community/tutorials/amazon-web-scraping-using-beautifulsoup
https://towardsdatascience.com/scraping-multiple-amazon-stores-with-python-5eab811453a8
Good to look at:
https://towardsdatascience.com/scraping-tripadvisor-text-mining-and-sentiment-analysis-for-hotel-reviews-cc4e20aef333 (good extra analysis, can inspire for ideas and in general Susan Li’s blogs are 🦚)
https://www.blog.datahut.co/post/scraping-amazon-reviews-python-scrapy () with Scrapy
