Mostly based on (Udemy, Jose Portilla’s NLP course )
Outputting on the screen
f strings (instead of .format() ). Used to print text.
print(f'His name is {name}.')
>>> His name is AndrewYou can also align spacing between the output. Use different quotation marks to avoid conflict:
print(f"Name: {d['a']} Andrew")Date Formatting
from datetime import datetime
today = datetime(year=2020, month=11, day=17)
print(f'{today:%B %d, %Y}')
>>> November 17, 2020Opening a file
# make sure to be at the right folder, or
# type pwd to find where are you
file = open('text.txt')
Now file is an open file object held in memory.Next is to read it()
# after executing your cursor is in the end of text.
my_file.read()
# to start again from the beginning
my_file.seek(0)
read line by line:
my_file.readlines()
>>> ['My name is Andrew.\n', 'and what are yours?']
Writing to a file
my_file = open('test.txt','w+') #removes original
my_file.write('I add some lines')
# good practice to do this when finish with a file
my_file.close()
#Append to a file, so cursor just shift to the end
my_file = open('text.txt','a+')
my_file.write('\nThis new line')
Aliases and context managers, assign temporary variable names.
with open('file.txt','r') as f:
lines = f.readlines()[0]
print(lines)
with open('test.txt','r') as f:
for line in f:
# the end='' argument removes extra line-breaks
print(line, end='')
Regular Expressions (regex)
help to find for specific strings in the text data. A bit strange syntax. You can test them here: https://regex101.com
import re
pattern = 'data'
# if smth is found, it returns
# <_sre.SRE.., otherwise NONE
matched = re.search(pattern, text)
# to check index info:
# matched.span() matched.start() matched.end()
To find all matches:
matches = re.findall(pattern, text)
Instead of giving exact pattern to be matched we can also define what to be found using some instructions. Those instructions for example can search for all occurrences of email, phone, url, etc. The format that is used here is r’pattern’ where r helps to \ treat not as an escape slash.

Example:
text = 'Roy phone number is 766-10-19'
phone = re.search(r'\d\d\d-\d\d-\d\d',text)
# We are searching for numbers with 3 digits
# followed by - then 2 digits and etc.
It is of course not convenient to write such code for longer strings. For that we can use quantifies.
Quantifiers define how many distinct characters to expect.
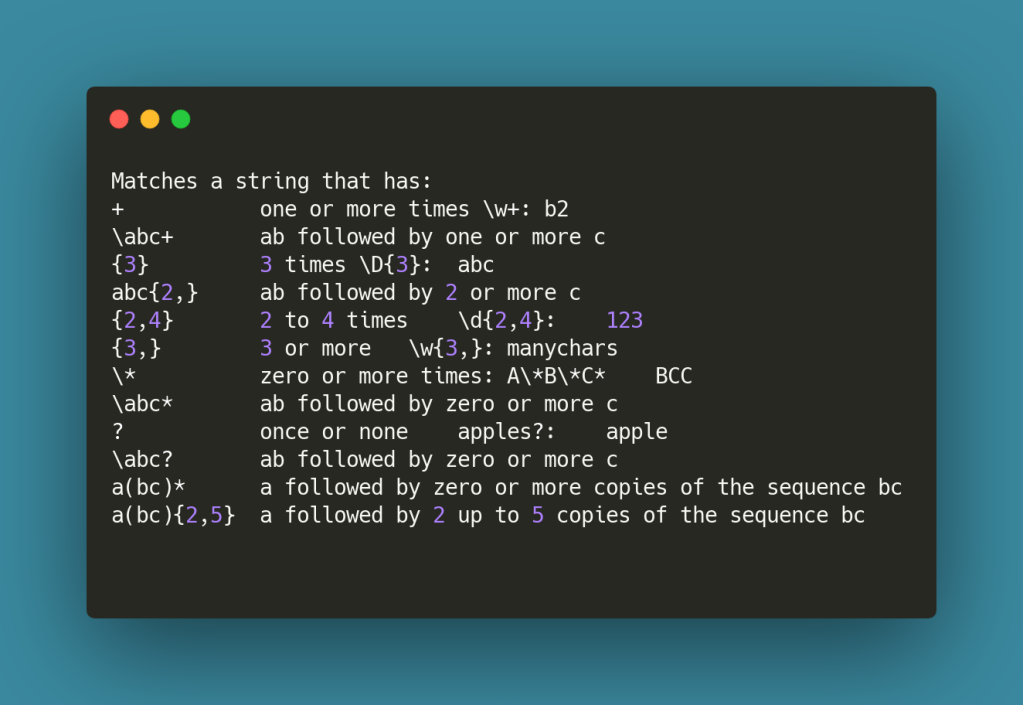
phone = re.search(r'd{3} -\d{2}-\d{2},text)
# We are searching for numbers with 3 digits
followed by - then 2 digits and etc.
text = 'bc absc abcbcbcc'
re.search(r'a(bc)*',text)
>>> <re.Match object; span=(3, 4), match='a'>
text = 'bc abccsc abcbcbcc'
re.search(r'abc+',text)
>>> <re.Match object; span=(3, 7), match='abcc'>
The Wildcard character in regex is dot (.). It is used to match any character placed there.
re.findall(r".ap","The apple in the app store, the cap in trap")
>>> ['ap', ' ap', 'cap', rap']
re.findall(r"..ap","The apple in the app sto, the cap in trap")
>>> ['e ap, 'e ap', ' cap', 'trap']
# One or more non-whitespace that ends with 'ap'
re.findall(r'\S+ap',"The apple in the app sto, the cap in trap")
>>> ['cap', 'trap']
Start with and ends with (for an entire string):
Use ^ for starting index:
# start with a number for entire string
re.findall(r'^\d','13 is the unlucky number.')
>>>['1']
re.findall(r'^The','the 13 is the unlucky number.')
[] #nothing is found
and $ as the end:
re.findall(r'\d$','This ends with a number 27') # end with a number
>>>['7']
Exclusion useful to remove something:
The ^ symbol in with brackets []. Anything inside the brackets is excluded
text = 'exclude 3 numbers like 1 or 4 or5'
# will print all except numbers
re.findall(r'[^\d]', text)
to get words:
re.findall(r'[^\d]+',text)
>>> ['exclude ', ' numbers like ', ' or ', ' or']
For removing punctuations:
text = 'string with . many & # punctuations!'
re.findall('[^!.? ]+',text)
clean = ' '.join(re.findall('[^!.? ]+',text))
>>> 'string with many & # punctuations'
OR operator | or [ ] . a(b|c) matches a string that has a followed by b or c (and captures b or c)a[bc] same but not capturing b or c.
re.findall(r"ba(t|d)","The bat went bad splat")
>>> ['t', 'd']
re.findall(r"ba[td]","The bat went bad splat")
>>> ['bat', 'bad']
Backslash for some characters
^.[$()|*+?{\
\d\$ -> will search for 3$Flags:
global (g) after first match, will not return (google more)
multi-line(m) instead of whole string, will match line.
insensitive (i) makes the matching case insensitive
/apPLe/i would match APpLeBrackets for Grouping
We group together words:
text = 'try find the hypen-words. banana-man'
re.findall(r'[\w]+-[\w]+',text)
>>> ['hypen-words', 'banana-man']
with()
a(?:b) will match the 'ab' in 'abc'
a(?=b) will only match 'a' in abc
a(?<foo>bc)
